Protegrity Anonymization Risk Metrics
Definitions
The following definitions are used for risk calculations:
- Data Provider or Custodian: The custodian of the data is responsible for controlling the sharing process by anonymizing the data. They also put in place additional controls to prevent the data from being misused or re‑identified.
- Data Recipient: Person or institution who receives the data from the data provider.
- Dataset: The collection of all records containing the data on subjects.
- Adversary: A data recipient who has the motivation and capability to attempt re‑identification of the data. They may intend to use the data in ways that could be harmful to individuals represented in the dataset.
- Target: Person whose details are in the dataset who has been selected by the adversary to focus the re-identification attempt on.
Types of risks
Protegrity Anonymization uses the Prosecutor, Journalist and Marketer risk models to access probability of re-identification attacks. A description of these risks are provided here.
- Prosecutor Risk: If the adversary can know that the target is in the dataset, then it is called Prosecutor Risk. The fact that target is part of dataset increases the risk of successful re-identification.
- Journalist Risk: When the adversary does not know for certain that the target is in the dataset then it is called Journalist Risk.
- Marketer Risk: Under Marketer Risk, the adversary attempts to re-identify as many subjects in the dataset as possible. If the risk of re-identifying an individual subject is possible, then the risk of multiple subjects being re-identified is also possible.
Relationship between the three risks
Prosecutor Risk >= Journalist Risk >= Marketer Risk
If the dataset is protected against the prosecutor and the journalist risk, depending on the adversary’s knowledge of target’s participation, then by default it is also protected against the marketer risk.
Measuring Risks
This section details the strategy used by Protegrity Anonymization to calculate risks.
For calculating risks, the population is the entire pool from which the sample dataset is drawn. In the current calculation of risk metrics, the population considered is the same as the sample. In case of journalist calculation, it is good to consider the population from a larger dataset from which the sample is drawn.
The following annotations are used in the calculations:
- Ra is the proportion of records with risk above the threshold which is at highest risk.
- Rb is the maximum probability of re-identification which is at maximum risk.
- Rc is the proportion of records that can be re-identified on an average which is the success rate of re-identification.
As part of the risk calculations, Protegrity Anonymization API calculates the following metrics:
- pRa is the highest prosecutor risk.
- pRb is the maximum prosecutor risk.
- pRc is the success rate of prosecutor risk.
- jRa is the highest journalist risk.
- jRb is the maximum journalist risk.
- jRc is the success rate of journalist risk.
- mRc is the success rate of marketer risk.
Risk Type | Equation | Notes |
|---|---|---|
Prosecutor | pRa = 1/n pRc = |J| / n |
|
Journalist | jRa = 1/n jRc = max ( |J| / |
|
Marketer | mRc = 1/n |
|
Measuring Journalist Risk
For Journalist Risk to be applied, the published dataset should be a specific sample.
There are two general types of re-identification attacks under journalist risk:
- The adversary is targeting a specific individual.
- The adversary is targeting any individual.
In case of journalist attack, the adversary will match the published dataset with another identification dataset, such as, voter registry, all patient data in hospital, and so on.
Identification of the dataset represents the population of which the published dataset is a sample.
For example, the sample published dataset is drawn from the identification dataset.

| Derived Risk Metrics | Equation | Risk Value |
|---|---|---|
| jRa | 1/n  fj x l(1 / FJ > T) fj x l(1 / FJ > T) | 0 |
| jRb | 1 / min(FJ) | 0.25 |
| jRc | max ( |J| / 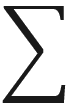 FJ) , 1 /n fj / FJ) FJ) , 1 /n fj / FJ) | 0.13 |
Calculation of jRa:
- T value is 0.33. Size of equivalence classes in the identity dataset are 10, 8, 14, 4, 2.
- Identity function returns 0 when value 1/F is less than τ value else 1.
- Identify function returns 0, 0, 0, 0, 1.
- Equivalence sizes in samples are 4, 3, 2, 1.
- Values of equivalence size / number of records are 0.4, 0.3, 0.2, 0.1.
- Product of the above value with identity function values are 0, 0, 0, 0.
- Value of jRa is 0.
Calculation of jRb:
- Minimum of equivalence size of identification dataset is 4
- Value of jRb is 0.25.
Calculation of jRc:
- Number of equivalence classes in 5 in identification dataset.
- Total records in identification dataset 38.
- Number of equivalence classes / total records = 5/38 = 0.131.
- Equivalence classes in sample / equivalence classes in identification dataset are 0.4, 0.375, 0/142857, 0/25.
- Total of above values 1.16.
- Above value / total records in sample = 1/16 / 10 = 0.116.
- Max (0.131, 0.116) = 0.131.
Measuring Marketer Risk
The use case for deriving the marketer risk is shown here.
| Derived Risk Metrics | Equation | Risk Value |
|---|---|---|
| mRc | 1/n fj /FJ | 0.116 |
Calculation of mRc:
- Equivalence classes in sample / equivalence classes in identification dataset are 0.4, 0.375, 0/142857, 0/25.
- Total of above values 1.16.
- Above value / total records in sample = 1/16 / 10 = 0.116.
- Value of marketer risk is 0.116.
Feedback
Was this page helpful?